Haciendo datos abiertos más accesibles con datasette
California recientemente liberó datos sobre las detenciones hechas por oficiales de las 8 agencias más grandes del estado. Estos datos cubren los meses de julio a diciembre del 2018. Esta fue la primera ola de divulgación de datos que entrará en vigencia en los años siguientes. Los datos cubrieron más de 1.8 millones de paradas en todo el estado. Si bien este es un paso en la dirección correcta, un solo archivo .csv de alrededor de 640 megabytes con más de 1.8 millones de filas y más de 140 columnas podría ser intimidante para algunas personas que se beneficiarían de la exploración de estos datos: líderes locales, periodistas, activistas y organizadores, por nombrar algunos.
El tercer principio de la carta internacional de datos abiertos es que los datos deben ser accesibles y utilizables.
Proporcionar los datos es el primer paso, pero para que sean utilizables y accesibles para la mayoría de las personas, no podemos simplemente publicar datos; debemos tener en cuenta la experiencia del usuario y desarrollar formas de facilitar la exploración y el uso de dichos datos.
En este tutorial, comparto una forma de hacerlo: usando datasette, una "herramienta de Python para explorar y publicar datos. Ayuda a las personas a tomar datos de cualquier forma o tamaño y publicarlos como un sitio web interactivo y explorable y con una API acompañante".
Tomamos los datos de detención policial lanzados recientemente por California, los limpiamos y transformamos a como sea necesario, y desplegamos una instancia de datasette en Heroku.
prólogo
La idea de explorar este conjunto de datos vino al escuchar el episodio del 3 de marzo del 2020 del podcast Pod Save the People. (minuto 4:12)
donde mencionan un artículo de The Appeal:
Boudin will announce a second directive today, also reviewed by The Appeal, on what are known as pre-textual stops, in which an officer stops someone for a minor offense or infraction, such as a traffic violation, in order to conduct an unrelated search for items like guns or drugs. According to the new policy, the DA's office will not prosecute possession of contraband cases when the contraband was collected as a result of an infraction-related stop, "where there is no other articulable suspicion of criminal activity." Any deviations from the policy should be made in writing and require approval from the DA or a chief of the criminal division. Additionally, the ban includes cases in which a person consented to a search "because of the long-standing and documented racial and ethnic disparities in law enforcement requests for consent to search," according to the directive.
- https://theappeal.org/san-francisco-da-to-announce-sweeping-changes-on-sentencing-policy-and-police-stops/
En el episodio, Sam Sinyangwe menciona que las personas negras y de color están siendo detenidas y registradas a tasas más altas, y que muchos de estos registros son lo que se conocen como 'registros consensuales', lo que significa que la policía no informa ninguna justificación para registrar a la persona mas que preguntar a esa persona si puede registrarlos y que la persona presuntamente da su consentimiento.
Esta gran disparidad racial es desgarradora pero no es sorpresa.
Cuando comencé a trabajar con el conjunto de datos me pareció un tanto íncomodo, no era fácil. El tamaño del conjunto de los datos hace que sea díficil trabajar con él para aquellas personas que no analizan datos programáticamente; ya sea con recursos pagados como stata y sas o gratuitos como python y R.
Esta información no esta diseñada para ser explorada fácilmente pero existen herramientas que pueden ayudar con eso.
💡Nota: AB-953, el proyecto de ley que requiere que las agencias reporten todos los datos sobre paradas al Procurador General, no requiere que los datos sean fácilmente "explorables" o "accesibles". El proyecto de ley requiere que los datos sean recopilados y reportados al Procurador General. Este conjunto de datos tal como es sirve para ese propósito.
sobre los datos

El conjunto de datos está compuesto por un archivo .csv de 641.4 MB que contiene 1.8 millones de filas y 143 columnas. Cada parada tiene un DOJ_RECORD_ID único y cada persona detenida tiene un PERSON_NUMBER. En total, hay 1,708,377 paradas en este conjunto de datos que involucran a 1,800,054 personas.
El conjunto de datos incluye información básica sobre cada parada (como duración, hora del día, ciudad más cercana, nombre de la agencia), información demográfica percibida (raza / etnia, género, edad, discapacidad), así como información sobre el motivo de detener, buscar, incautar, acciones tomadas durante la detención, contrabando o evidencia encontrada, etc. Para obtener información más detallada sobre el conjunto de datos, se puede leer el archivo README que reunió el Departamento de Justicia y el Informe Anual 2020.
💡Nota: Los datos reflejan la percepción del oficial. Son datos demográficos percibidos, es decir, si pareces hispano, te marcan como hispano. Si pareces de 27 años te marcan de 27 años. Este es otro problema para otra ocasión pero hay que tenerlo en mente cuando trabajamos con estos datos.
Esta es la Ola I de una serie de datos de la Racial and Identity Profiling Act (RIPA) que se lanzarán en los años siguientes. Los datos publicados sobre esta ola pertenecen a las 8 agencias de aplicación de la ley (LEA, por sus siglas en inglés) más grandes de California (las que emplean a más de 1,000 oficiales). Estas LEA (y su parte de las observaciones totales) son:
| Law enforcement agency (LEA) | N | % |
|---|---|---|
| California Highway Patrol | 1,033,421 | 57.4% |
| Los Angeles Police Department | 336,681 | 18.7% |
| Los Angeles Sheriff Department | 136,635 | 7.59% |
| San Diego Police Department | 89,455 | 4.97% |
| San Bernardino Sheriff Department | 62,433 | 3.47% |
| San Francisco Police Department | 56,409 | 3.14% |
| Riverside Sheriff Department | 44.505 | 2.47% |
| San Diego Sheriff Department | 40,515 | 2.25% |
sobre datasette
Datasette es una herramienta para explorar y publicar datos. Ayuda a las personas a tomar datos de cualquier forma o tamaño y publicarlos como un sitio web interactivo y explorable y la API que lo acompaña. Datasette está dirigido a periodistas de datos, conservadores de museos, archiveros, gobiernos locales y cualquier otra persona que tenga datos que deseen compartir con el mundo. Es parte de un ecosistema más amplio de herramientas y complementos dedicados a hacer que trabajar con datos estructurados sea lo más productivo posible .
- datasette.readthedocs.io
datasette es el motor que impulsa este proyecto. En resumen, toma una base de datos sqlite y crea un sitio web interactivo y explorable y API que lo acompaña. Para preparar los datos, utilizamos csvs-to-sqlite, otra herramienta del ecosistema datasette que toma archivos CSV y crea bases de datos sqlite a partir de ellos.
Puedes encontrar ejemplos de datasettes públicos en el wiki del repositorio en GitHub. Aquí se encuentra uno siriviendo los conjuntos de datos publicados por FiveThirtyEight (puedes encontrarlos en su repositorio de GitHub): https://fivethirtyeight.datasettes.com/
La página principal muestra la licencia y la fuente de la base de datos. También provee acceso rápido a algunas de sus tablas.
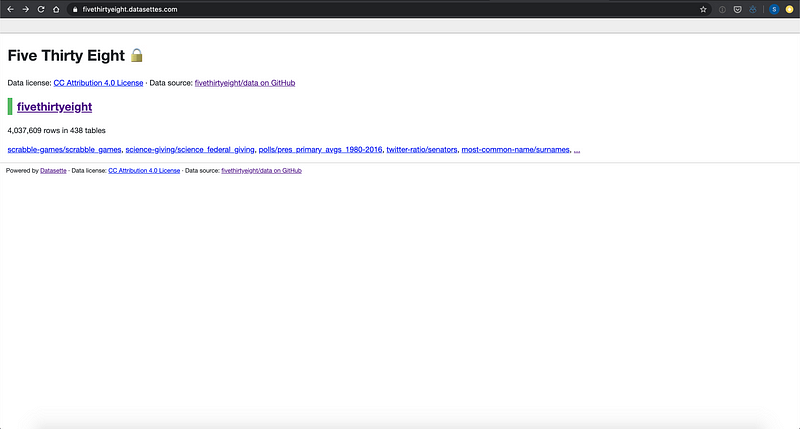
Si haces clic en el nombre de la base de datos, proporcionará una vista de todas sus tablas y un cuadro de texto para que ejecute consultas SQL personalizadas. Esta es una de las características que hace que datasette sea una herramienta tan poderosa.

Si haces clic en una de las tablas, verás las facetas sugeridas, un botón de filtro fácil de usar, un enlace JSON y CSV que proporcionará la tabla como uno de esos formatos (esto significa que puede usar esto como API) y una descripción de la tabla. En este caso, la descripción contiene una tabla HTML con encabezados y definiciones.

Si haces clic en el botón "View and edit SQL", volverás a tener acceso a un cuadro de texto para escribir sus propias consultas.
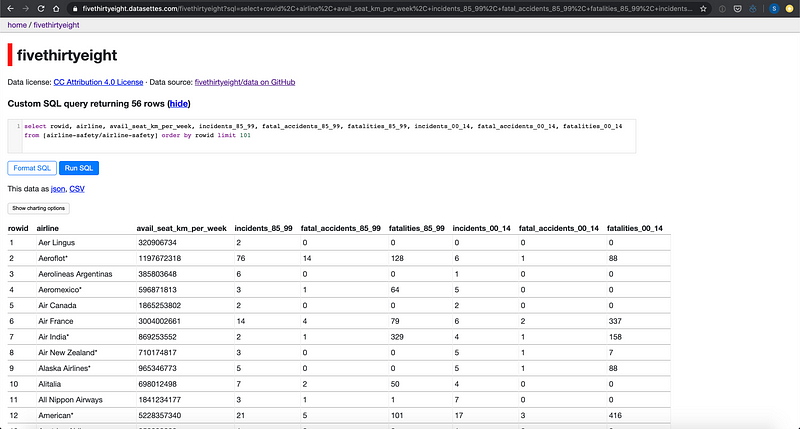
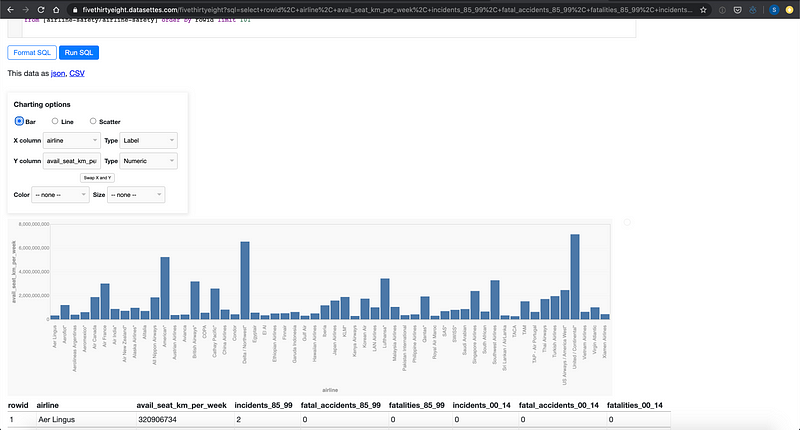
datasette es parte de un ecosistema de herramientas y plugins. Puedes agregar el plugin datasette-vega (repo) para agregar visualizaciones interactivas de la tabla (hechas con altair)
Así es como se ve un sitio web básico de datasette pero datasette es altamente personalizable. Tomemos, por ejemplo, el datasette de The Baltimore Sun para que las personas exploren los registros de salarios públicos que se actualizan anualmente.
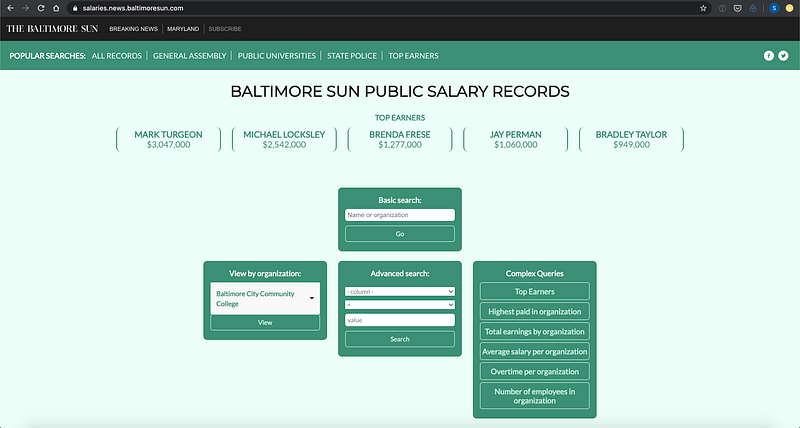
Esto esta corriendo datasette detrás de cámaras pero The Baltimore Sun agrego sus propias plantillas y archivos CSS y JS. Para aprender más sobre como personalizar datasette visita https://datasette.readthedocs.io/en/stable/custom_templates.html
paso, paso a pasito
Esta sección es una descripción más técnica del proyecto. La preparación y despliegue de datos con datasette es bastante sencillo y se puede dividir en tres fases:
- Adquirir los datos
- Preparar los datos
- Servir los datos
adquiriendo los datos
Los datos se obtuvieron del sitio web de Open Justice del Departamento de Justicia de California: https://openjustice.doj.ca.gov/data. El sitio web proporciona un enlace para descargar los datos (por lo menos desde 5 de mayo de 2020, cuando lo descargué para este proyecto). Para obtener más información sobre los datos en sí, puede leer la sección Acerca de los datos en el repositorio de GitHub del proyecto.
preparando los datos
El CSV original es de mas de 640 MB así que el primer paso es dividirlo en 15 archivos para que cada uno pueda subirse a GitHub en este repositorio.
import pandas as pd
import numpy as np
from pathlib import Path
THIS_FILE = Path(__file__)
THIS_DIR = THIS_FILE.parent
EXTERNAL_DATA = THIS_DIR.joinpath("./../../data/external/")
INTERIM_DATA = THIS_DIR.joinpath("./../../data/interim/")
FULL_DB = "RIPA Stop Data 2018.csv"
data = pd.read_csv(EXTERNAL_DATA.joinpath(FULL_DB))
dfs = np.array_split(data, 15)
for idx,df in enumerate(dfs):
print(f"Saving dataset #{idx}")
df.to_csv(INTERIM_DATA.joinpath(f"ripa-2018-part-{idx}.csv"), index = False)
💡¿Por qué? Nomás por si desaparece misteriosamente de la fuente original...
Sin embargo, debido a que el conjunto de datos es demasiado grande para servir como una sola tabla (1,8 millones de filas por 143 columnas), también se dividió en tablas más pequeñas. Esto significa que tomamos variables relacionadas (basadas en sus sufijos) y las extrajimos en sus propias tablas. Por ejemplo, variables relacionadas con el género como G_FULL,G_MALE, G_FEMALE,G_TRANSGENDER_MAN, G_TRANSGENDER_WOMAN,G_GENDER_NONCOMFORMING, y G_MULTIGENDER se extrajeron de la tabla "principal "y se agregaron a una tabla de género en la base de datos.
Estas se pueden volver a unir a la tabla principal utilizando un UNIQUE_ID asignado a ellas.
Este script es demasiado grande para incluir en este blog sin crear una distracción inecesaria pero puedes ver las 91 líneas de código aquí: https://github.com/chekos/RIPA-2018-datasette/blob/master/src/data/break_down_database.py
A cada observación o fila de este conjunto de datos se le asigna un DOJ_RECORD_ID y unPERSON_NUMBER. Estos son exclusivos de la parada y las personas detenidas, respectivamente. Esto significa que podríamos combinarlos para crear un 'ID ÚNICO' para cada fila que podríamos usar para unir tablas. Sin embargo, esto termina siendo una cadena de 22 caracteres que es innecesariamente grande. Para facilitar las cosas, a cada fila se le asigna una identificación numérica que comienza en 1,000,000. Comenzar en un millón es completamente arbitrario, podríamos haber comenzado en cero, pero debido a que hay 1.8 millones de filas, tomamos la decisión de que cada identificación numérica sea de siete dígitos. Este UNIQUE_ID numérico nos permite unir tablas juntas y no es una gran adición a la base de datos en términos de memoria.
Una vez que se ha creado este ID_ÚNICO, podemos extraer columnas de la tabla "principal" en sus propias tablas y guardarlas como archivos CSV individuales con la certeza de que cada observación puede coincidir en estas nuevas tablas.
Luego usamos csvs-to-sqlite para crear una base de datos sqlite donde cada CSV es una tabla. En este paso, también incluimos el archivo Appendix B Table 3.csv obtenido también del sitio web del DOJ y cualquier otra tabla complementaria que podríamos haber creado para acompañar el conjunto de datos.
csvs-to-sqlite data/processed/*.csv "data/external/Appendix B Table 3.csv" datasette/ripa-2018-db.db
sirviendo los datos
Después de preparar los datos y crear una base de datos sqlite usamos datasette para servirlos como un sitio web interactivo y su API. Esto es tan fácil como ejecutar
Pero para este proyecto personalizamos nuestro datasette un poco.
Incluimos un tîtulo, una descripción, la url de la fuente de los datos y archivos CSS y JS. Puedes explorar el archivo metadata.json en el repositorio datasette/metadata.json para ver que más hicimos.
También incluímos lo que datasette llama canned queries, lo que sería "consultas almacenadas" (?). Estas son consultas de SQL incluídas en tu instancia que aparecen al fondo de tu página principal y tiene su propio URL para facilitar el acceso. Estas consultas las incluimos porque muestran información útil y/o interesante de los datos. Algunas de ellas son consultas que computan información especifica publicada en el reporte anual del 2020.
También modificamos algunas plantillas de datasette, especificamente base.html y query.html. La primera fue modificada para incluir metadatos en la etiqueta <head> (descripción del sitio, por ejemplo, para cuando se comparta un enlace). La segunda fue modificada para incluir un botón debajo del cuadro de texto donde escribes tus consultas de SQL. Este botón sirve para facilitar las sugerencias de consultas para el repositorio. Al hacer clic, se abre otra ventana en tu navegador que crea un nuevo issue en github con la consulta de SQL que acabas de ejecutar.
También cambiamos algunas opciones para datasette:
default_page_size:50- Muestra solo 50 resultados por páginasql_time_limit_ms:30000- Un límite de 30 segundos para ejecutar consultas (es el límite de tiempo de Heroku)facet_time_limit_ms:10000- El tiempo límite que datasette debería usar calculando una posible faceta de tu tabla (el default es de 200ms pero nuestro conjunto de datos es tan grande que lo expandimos a 10 segundos)
El código por ejecutar es:
datasette ripa-2018-db.db \\
-m metadata.json \\
--extra-options="--config default_page_size:50 --config sql_time_limit_ms:30000 --config facet_time_limit_ms:10000"
desplegando en heroku
Aquí hay una descripción general de alto nivel del proceso
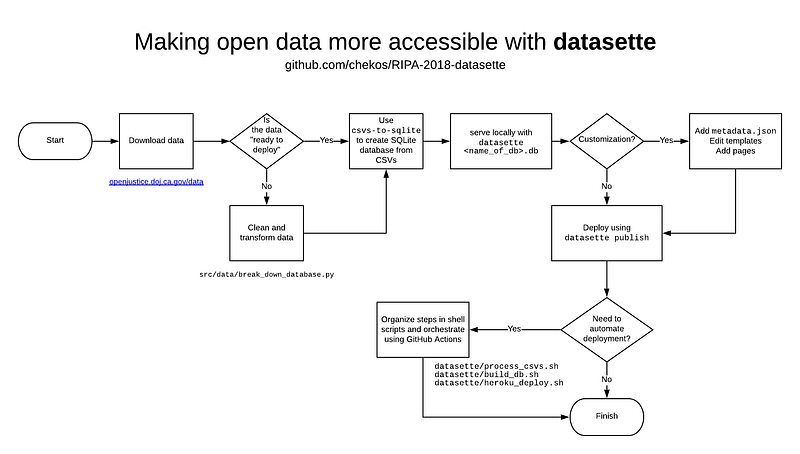
Hasta ahora, utilizamos un código de Python para procesar nuestros datos (creando un UNIQUE_ID y desglosando el conjunto de datos original con 143 columnas en varios archivos.csv más pequeños) y también utilizamos csvs-to-sqlite para construir nuestra base de datos ripa-2018-db.db de esos archivos.csv. Hasta ahora, hemos estado interactuando con nuestro datasette ejecutando el comando datasette ripa-2018-db.db que ejecuta un servidor local. Para que nuestro datasette esté disponible para el mundo, tenemos que implementarlo en línea y, por suerte, es muy, muy fácil de hacer, ya que datasette ya incluye un comando de publicación.
Con datasette puedes publicar directamente a Heroku, Google Cloud Run, o Fly (por lo menos desde la versión 0.42 que es la que utilizamos en este proyecto). Debido a que tengo experiencia previa en la implementación de heroku, me pareció la más fácil de las tres, pero todas son excelentes opciones y la documentación es fácil de seguir.
Implementar en Heroku fue tan fácil como ejecutar casi el mismo comando utilizado para servir nuestro datasette localmente.
datasette publish heroku ripa-2018-db.db \\
--name ripa-2018-db \\
-m metadata.json \\
--extra-options="--config default_page_size:50 --config sql_time_limit_ms:30000 --config facet_time_limit_ms:10000"
💡 Nota la bandera
--nameque espcifíca el nombre de nuestra aplicación en Heroku. Esto significa que la publicará a ripa-2018-db.herokuapp.com y sobreescribirá cualquier aplicación previa ahí.
Para ejecutar esto, necesitará una cuenta heroku e instalar la herramienta de línea de comandos de heroku. Datasette (usando el la herramienta de línea de comandos) te pedirá que inicies sesión y abrirá una ventana del navegador para que lo haga. Después de iniciar sesión, se encargará del resto.
¡Listo! En este punto, hemos publicado con éxito nuestro datasette en heroku y podemos visitar ripa-2018-db.herokuapp.com o ripa-2018.datasettes.cimarron.io/
Este será el final de este proceso para muchas personas. Adquirimos y transformamos con éxito algunos datos y los desplegamos en la nube para que otros puedan explorar e interactuar con ellos. También hemos incluido una descripción HTML que describe nuestro datasette para los usuarios e incluso algunas consultas almacenadas para que las personas reproduzcan algunos de los hechos publicados en el Informe Anual 2020.
automatizando todo
Si bien los datos subyacentes que estas publicando no cambian con frecuencia, es posible que desees automatizar la implementación de su instancia de datasette por muchas razones. Por ejemplo, cuando comencé este proyecto, datasette estaba en la versión 0.40 y en el momento en que escribo esta publicación está en la versión 0.42. Para la mayoría de las versiones no necesitarás actualizar tu instancia de datasette, pero la versión 0.41 incluía la capacidad de crear páginas personalizadas (changelog).
For example, adding a template file called
templates/pages/about.htmlwill result in a new page being served at/abouton your instance.
Esto significa que podemos agregar mucho más contexto en nuestra instancia para los usuarios. Tal vez incluya una guía paso a paso para ayudar a las personas a contribuir al proyecto, otros enlaces útiles o una página simple para presentarse para que las personas que usan estos datos aprendan un poco más sobre ti.
También es posible que desee incluir más consultas almacenadas o corregir un error ortográfico en su descripción. Cualquiera sea la razón, la implementación automática es fácil de lograr. En definitiva, todo lo que necesita es ejecutar datasette heroku publishing, que es un caso de uso perfecto para las GitHub Actions.
🚨 Advertencia / Nota: Esta próxima parte se vuelve mucho más técnica rápidamente. GitHub Actions es un tema más avanzado. Si no necesitas / deseas actualizar su instancia de datasette recientemente implementada regularmente, no recomendaría pensar en las GitHub Actions por el momento.
GitHub Actions
GitHub Actions help you automate your software development workflows in the same place you store code and collaborate on pull requests and issues. You can write individual tasks, called actions, and combine them to create a custom workflow. Workflows are custom automated processes that you can set up in your repository to build, test, package, release, or deploy any code project on GitHub.
- https://help.github.com/en/actions/getting-started-with-github-actions/about-github-actions
No entraremos muy a fondo en las acciones de GitHub en esta publicación. Lo que necesitas saber es que con las GitHub Actions puede ejecutar tareas en paralelo o en secuencia, y estos se desencadenan por eventos de GitHub como empujar tu código a una branch, abrir una pull request, comentar en un issue o una combinación de muchos.
Estos existen en sus repositorios de GitHub en .github/workflows/ generalmente en forma de archivos yaml. La estructura básica es la siguiente.
name: Example of simple GitHub Action
on:
push:
branches: [master]
jobs:
say-hi:
runs-on: ubuntu-latest
steps:
- name: Echo Hello World
run: |
echo "Hello World!"
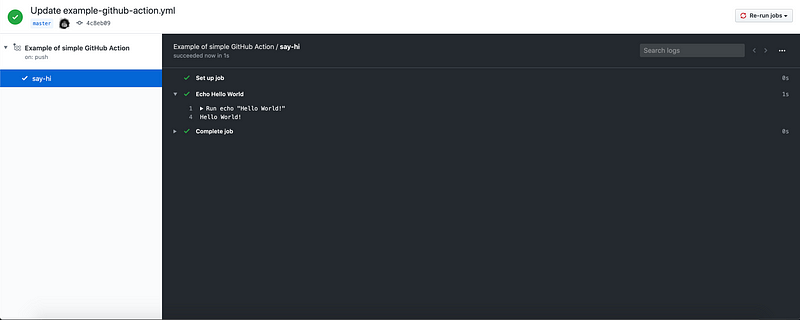
Esta acción se activará cada vez que haya un impulso en su rama maestra y ejecutará el trabajo say-hi que se ejecuta en una máquina virtual (VM) ubuntu disponible. En esa VM ejecutará el código echo "Hello World!"
Puede ver los resultados / registros de sus acciones en la pestaña Actions de tu repositorio.
Podrías cambiar facilmente echo "Hello World!" con
datasette publish heroku ripa-2018-db.db \\
--name ripa-2018-db \\
-m metadata.json \\
--extra-options="--config default_page_size:50 --config sql_time_limit_ms:30000 --config facet_time_limit_ms:10000"
o mejor aún puedes guardar tu código en un script de bash llamado heroku_deploy.sh y ejecutar sh heroku_deploy.sh como ejecutarías echo "Hello World!"
Afortunadamente, Heroku ya está instalado en nuestro corredor de la GitHub Action (ubuntu-latest), por lo que todo lo que tenemos que hacer es iniciar sesión, instalar el complemento heroku-builds y ejecutar nuestro script heroku_deploy.sh.
💡 Aprendí sobre la necesidad de instalar
heroku-buildsdespués de que las acciones de GitHub fallaran un par de veces. No estoy seguro de que esté documentado en datasette o en la documentación de GitHub Actions.
Hasta ahora, nuestra GitHub Action se ve así:
name: Example of simple GitHub Action
on:
push:
branches: [master]
jobs:
publish-to-heroku:
runs-on: ubuntu-latest
steps:
- name: Publish to Heroku
run: |
heroku container:login && heroku plugins:install heroku-builds && sh heroku_deploy.sh
Esto, sin embargo, aún no está listo para funcionar. Para automatizar el inicio de sesión, debe incluir la variable de entorno HEROKU_API_KEY. Esto es posible mediante el uso de GitHub Secrets.
Para crear tu API key necesitas tener instalada la herramienta de heroku para la línea de comando localmente. Ejecuta el comando heroku authorizations:create y añadela a tu repositorio en Settings > Secrets. Llámalo HEROKU_API_KEY.
Para que su GitHub Action tenga acceso a ella, debe agregar la siguiente línea a su archivo yaml
name: Example of simple GitHub Action
on:
push:
branches: [master]
jobs:
publish-to-heroku:
runs-on: ubuntu-latest
steps:
- name: Publish to Heroku
env: ${{ secrets.HEROKU_API_KEY }}
run: |
heroku container:login && heroku plugins:install heroku-builds && sh heroku_deploy.sh
¡Listo! Ahora, cada vez que empujes código a tu repositorio en la branch "master", implementará una nueva versión de tu datasette. Esto significa que puede actualizar su metadata.json, por ejemplo, con una nueva consulta almacenada o agregar una nueva página a tustemplates/pages.
Para este proyecto, tengo algunos pasos adicionales (pasos de GitHub Action, es decir) que procesan los datos, construyen la base de datos sqlite3 y la despliegan en heroku cada vez que hay un nuevo "commit" en "master". También incluyo un par de scripts de Python que leen un archivo yaml separado donde tengo todas las consultas almacenadas y las agrego a un updated_metadata.json. Esto es para mantener las cosas un poco más limpias, cada consulta almacenada tiene un título, html_description y una larga consulta SQL; Es más fácil de mantener como un archivo separado, en mi opinión.
Puedes ver el archivo yaml de mi GitHub Action aquí https://github.com/chekos/RIPA-2018-datasette/blob/master/.github/workflows/main.yml
bonus
using github issues to suggest queries
Si visitas
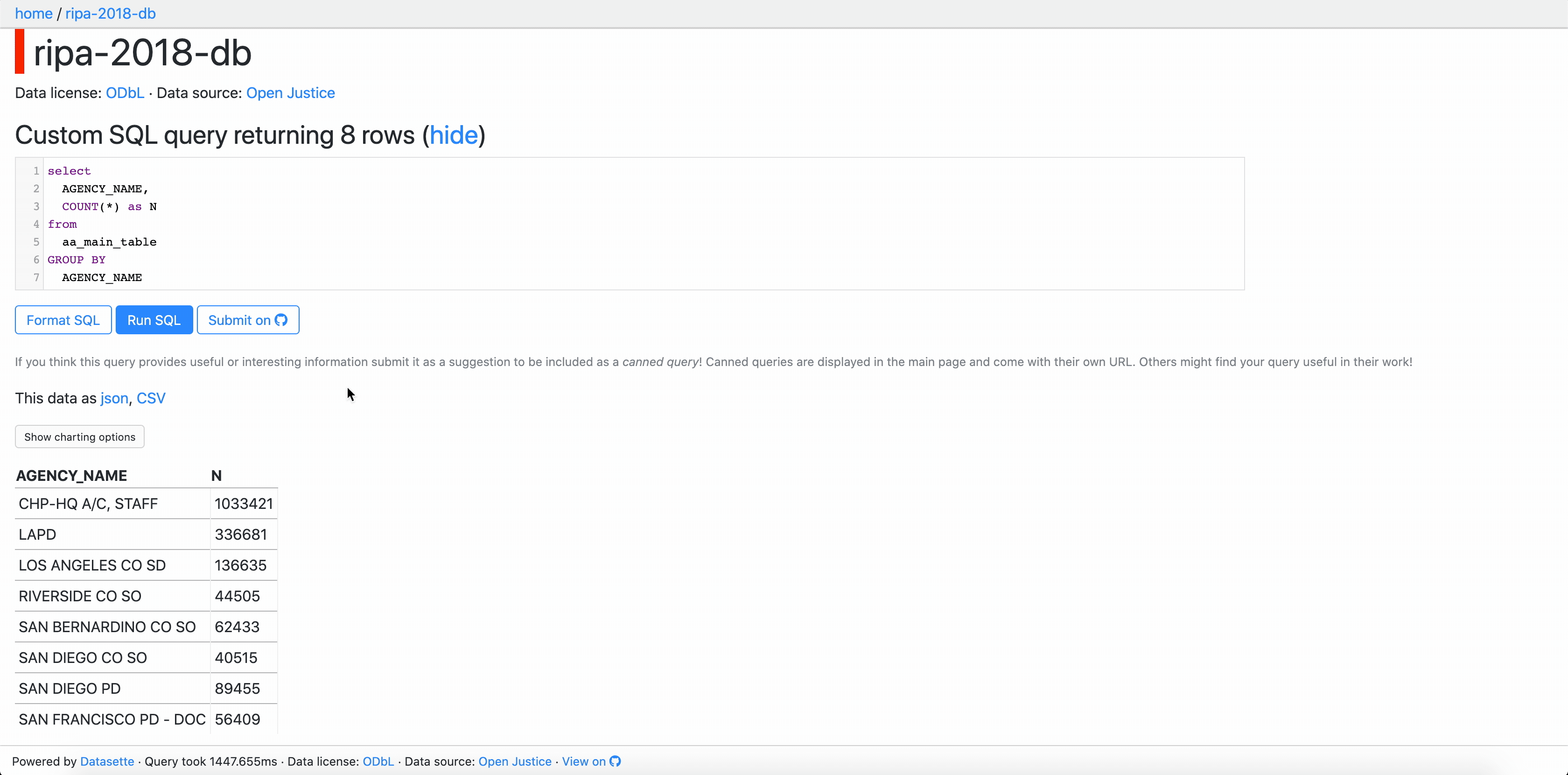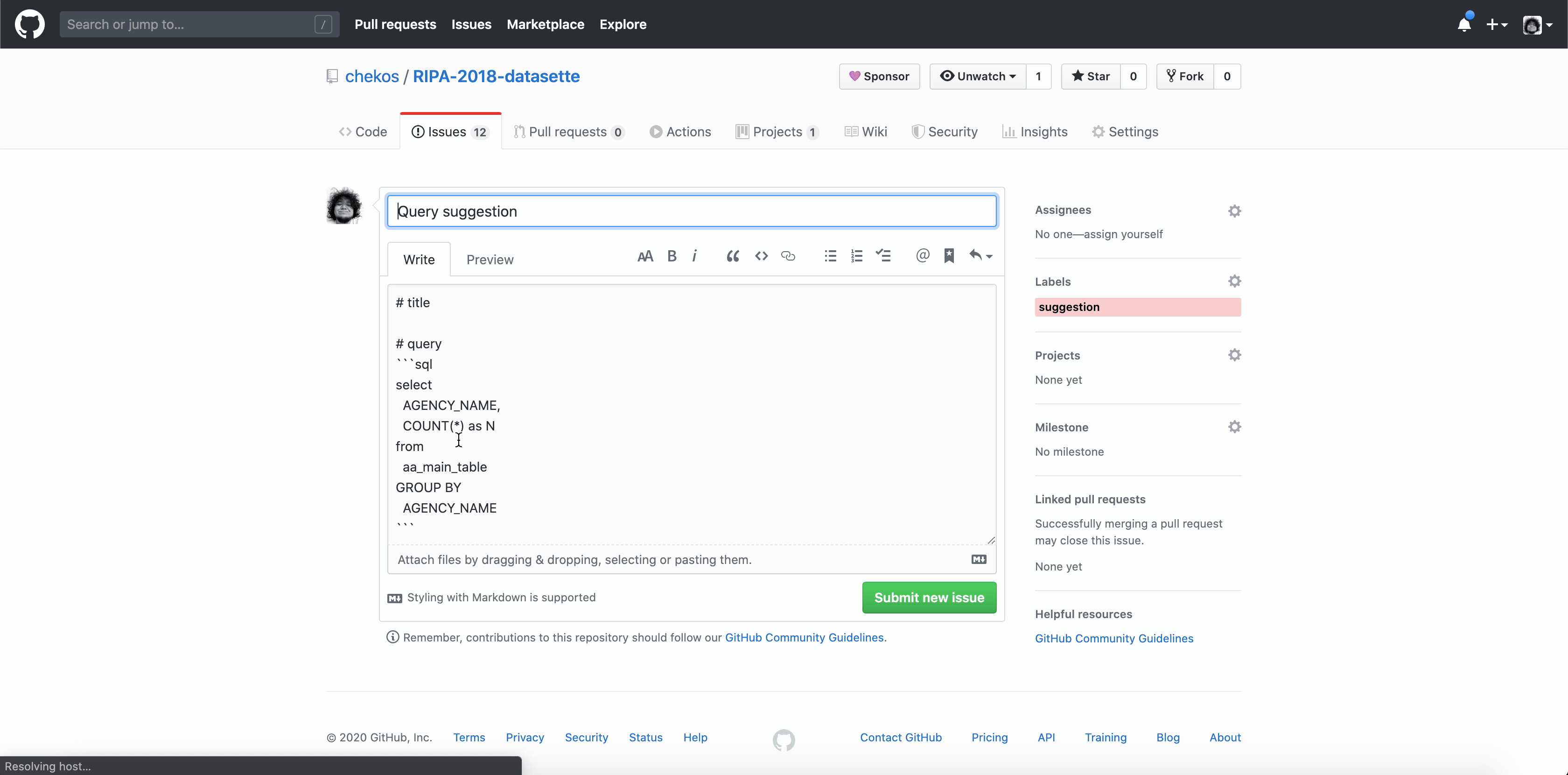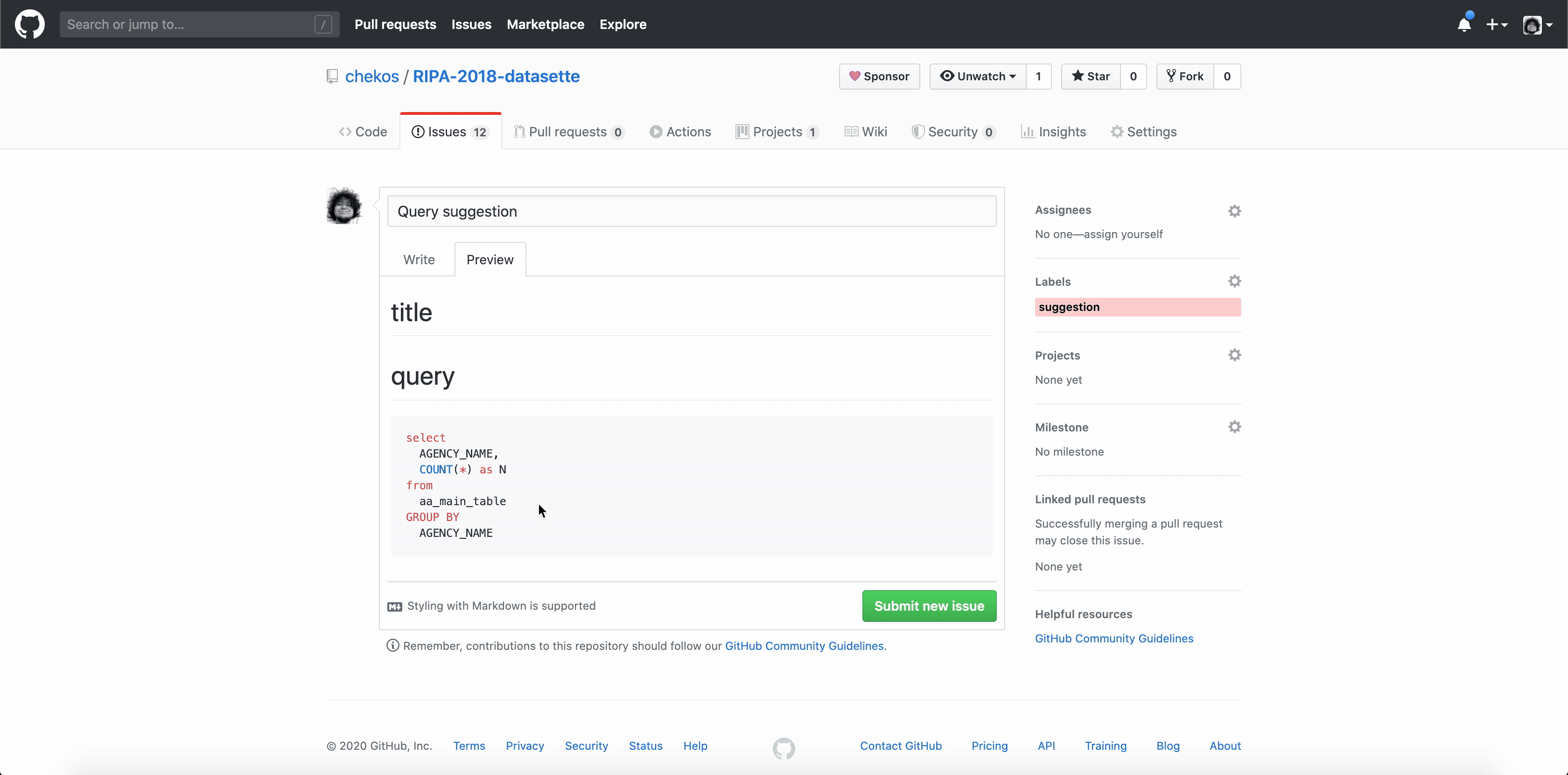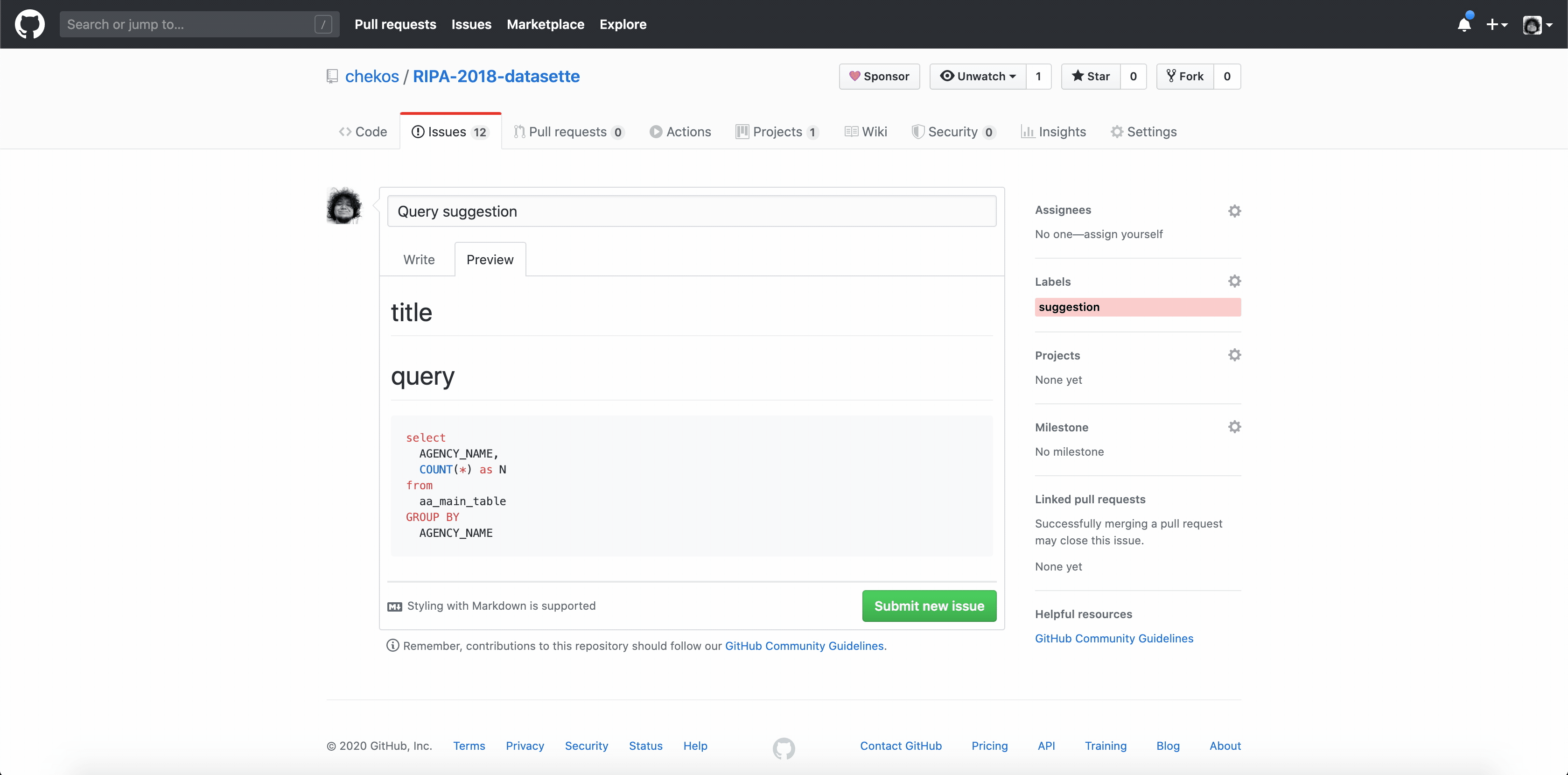
Esto se hace mediante un ajuste de la plantilla query.html. Datasette usa jinja2 y en realidad está pasando la consulta SQL como un parámetro de consulta de URL, lo que significa que puede acceder a él usando request.query_string.split('sql =')[- 1]
Ya que tienes acceso a la consulta es facil crear un enlace directo a un issue nuevo en tu repo
{% raw %}
{% set link_to_new_issue = "<https://GitHub.com/><YOUR_USERNAME>/<YOUR_REPO>/issues/new?title=Query+suggestion&labels=suggestion&body=" + <QUERY_FOR_ISSUE> %}
{% endraw %}
Así se ve en query.html
... {% set query_for_issue = "%23+title%0A%0A%23+query%0A%60%60%60sql%0A" +
request.query_string.split('sql=')[-1] + "%0A%60%60%60" %} {% set
link_to_new_issue =
"https://GitHub.com/chekos/ripa-2018-datasette/issues/new?title=Query+suggestion&labels=suggestion&body="
+ query_for_issue %}
<p>
<button id="sql-format" type="button" hidden>Format SQL</button>
<input type="submit" value="Run SQL" />
<button type="button" class="btn btn-secondary btn-sm">
<a href="{{ link_to_new_issue }}" target="_blank"
>Submit on <i class="fab fa-github"></i
></a>
</button>
</p>
...
{% endraw %}
cuanto tiempo tomó
Todo el proceso tomó alrededor de 20 horas en total, distribuidas en 3 a 4 semanas. La mayor parte estaba planeando y orquestando todo el proceso automatizado usando GitHub Actions. Espero que este tutorial te ayude a ahorrar esas horas extra. Al igual que cualquier otro proyecto de datos, es mejor pasar un tiempo por adelantado pensando y planeando detalladamente cada paso del proceso.
llamado a la acción
El mundo ha cambiado. La idea de este proyecto se me ocurrió a mediados de abril y no creé el repositorio de GitHub hasta finales de mes. No comencé a escribir este tutorial hasta la segunda mitad de mayo. Todo ha cambiado desde entonces.
Todos los días en las redes sociales vemos videos y leemos historias sobre autoridades que abusan de su poder y ejercen violencia contra personas inocentes. No son todos, pero no debería ser ninguno de ellos.
Creo en los datos como una herramienta para el cambio, para la rendición de cuentas, para la transparencia. El mundo ha cambiado para siempre por la tecnología y los datos. Como tecnólogos, nerds de datos, expertos en políticas o cualquier etiqueta autoascrita que elijan, tu que me lees, tenemos la responsabilidad de que nuestros pares usen nuestras habilidades, nuestras poderosas herramientas, nuestro conocimiento para hacer del mundo un lugar mejor porque podemos.
Te pido que pienses en el papel que desempeñas. ¿Harás del mundo un lugar mejor con las herramientas que estás construyendo, por favor?
Te dejo con el siguiente pensamiento de Data4BlackLives:
Data for Black Lives es un movimiento de activistas, organizadores y matemáticos comprometidos con la misión de utilizar la ciencia de datos para crear un cambio concreto y medible en la vida de las personas negras. Desde el advenimiento de la informática, la big data y los algoritmos han penetrado prácticamente todos los aspectos de nuestra vida social y económica. Estos nuevos sistemas de datos tienen un enorme potencial para empoderar a las comunidades de color. Herramientas como el modelado estadístico, la visualización de datos y el abastecimiento público, en las manos correctas, son instrumentos poderosos para combatir el sesgo, construir movimientos progresivos y promover el compromiso cívico. Pero la historia cuenta una historia diferente, una en la que los datos se utilizan con demasiada frecuencia como un instrumento de opresión, que refuerza la desigualdad y perpetúa la injusticia. Redlining fue una empresa basada en datos que resultó en la exclusión sistemática de las comunidades negras de los servicios financieros clave. Las tendencias más recientes como la vigilancia predictiva, las sentencias basadas en el riesgo y los préstamos abusivos son variaciones preocupantes sobre el mismo tema. Hoy, la discriminación es una empresa de alta tecnología.
- d4bl.org
Este artículo fue publicado originalmente en inglés en la publicación Towards Data Science, Making open data more accessible with datasette